从零到一 人工智能全流程技术体系与实战指南
随着人工智能技术的飞速发展,越来越多的人希望踏入这一充满潜力的领域。本系列教程旨在为零基础的学习者提供一个清晰、系统的学习路径,涵盖从理论到实战的全流程技术体系。我们将深入探讨人工智能的基础软件开发、自然语言处理(NLP)、GPT预训练技术以及数据标注等核心概念,帮助你从入门走向精通。
人工智能基础软件开发
人工智能基础软件开发是构建智能系统的基石。它涉及编程语言(如Python、C++)、算法设计、数据结构以及机器学习框架(如TensorFlow、PyTorch)的使用。初学者应从学习Python开始,因为其简洁易读的语法和丰富的库(如NumPy、Pandas)使其成为AI开发的首选语言。掌握基础后,可以进一步学习如何使用框架搭建神经网络模型,实现图像分类、语音识别等基础任务。这一阶段的目标是培养编程思维和解决实际问题的能力。
自然语言处理(NLP)简介
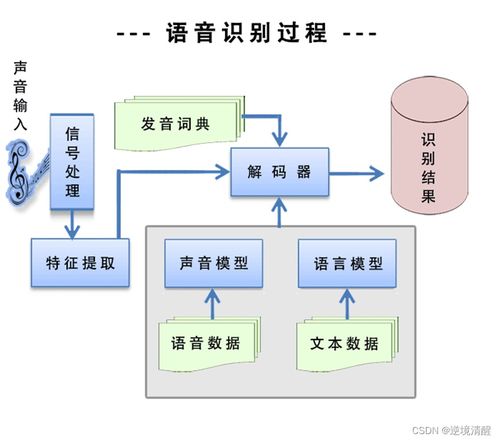
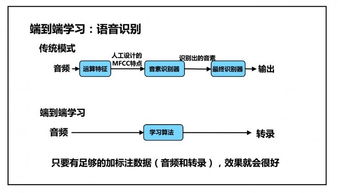
自然语言处理(NLP)是人工智能的一个重要分支,专注于让计算机理解、处理和生成人类语言。NLP的应用广泛,包括机器翻译、情感分析、智能客服等。其核心技术包括词嵌入(如Word2Vec)、序列建模(如RNN、LSTM)以及注意力机制。预训练模型(如BERT、GPT)的出现大幅提升了NLP任务的性能。学习NLP需要掌握语言学基础、统计方法以及深度学习模型,通过实战项目(如构建聊天机器人)可以加深理解。
GPT预训练技术解析
GPT(Generative Pre-trained Transformer)是一种基于Transformer架构的预训练语言模型,由OpenAI开发。预训练是指在大规模文本数据上训练模型,使其学习语言的通用模式,然后通过微调适应特定任务(如文本生成、问答)。GPT的核心优势在于其生成能力,能够根据上下文生成连贯的文本。例如,GPT-3拥有1750亿参数,可以完成写作、编程等多种任务。理解GPT需要熟悉Transformer的自注意力机制,以及如何利用预训练-微调范式提升模型效率。对于学习者来说,可以从使用开源的小型GPT模型开始,逐步探索其原理和应用。
数据标注的重要性与方法
数据标注是人工智能项目中的关键环节,涉及为原始数据(如图像、文本)添加标签,以供模型训练使用。高质量的数据标注直接影响模型的准确性和鲁棒性。常见的数据标注类型包括图像分类、目标检测、文本情感标注等。标注方法可以是手动、半自动或全自动,其中众包平台(如Amazon Mechanical Turk)常用于大规模标注。在实践中,学习者应了解标注规范设计、质量评估流程以及伦理考量(如隐私保护)。通过参与实际标注项目,可以深入理解数据在AI系统中的核心作用。
全流程实战指南
从零基础进军人工智能领域,建议遵循以下步骤:学习编程和数学基础(线性代数、概率论);掌握机器学习与深度学习理论;然后,选择NLP或计算机视觉等方向深入实践;接着,参与数据标注和模型训练项目;关注最新技术(如GPT-4)并持续迭代。实战中,可以利用Kaggle竞赛、开源项目积累经验,同时保持对伦理和社会影响的思考。
人工智能是一个跨学科的领域,需要理论与实践相结合。通过本教程的引导,你将建立起全面的技术视野,并能够逐步应用于实际场景中。记住,持续学习和动手实践是成功的关键!
最新产品