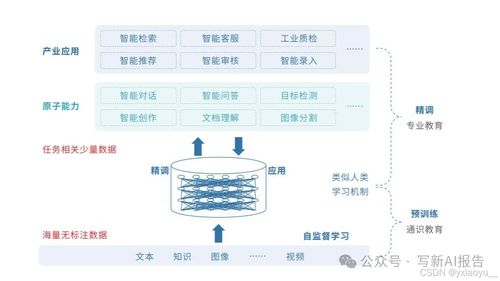
吴恩达NIPS 2016演讲 利用深度学习开发人工智能应用的基本要点
在2016年的神经信息处理系统大会(NIPS)上,人工智能领域的权威学者吴恩达(Andrew Ng)发表了一场极具影响力的演讲,重点阐述了利用深度学习技术开发人工智能应用的核心原则与基本要点。这场演讲不仅为当时快速发展的AI领域提供了清晰的实践指南,其见解至今仍对人工智能基础软件的开发具有深刻的指导意义。
一、核心要点:以数据为中心的AI开发
吴恩达在演讲中强调,构建成功的AI应用,其核心已经从以模型为中心(Model-Centric)转向了以数据为中心(Data-Centric)。这意味着,相比于花费大量精力调整和优化复杂的模型架构,开发团队更应该专注于获取高质量、大规模、标注良好的数据。他指出,在许多实际应用场景中,一个相对简单的模型搭配上卓越的数据集,其性能往往能超越一个复杂模型搭配普通数据。这一观点重塑了AI项目开发的优先级。
二、基本流程与迭代循环
演讲中勾勒出了一个高效的AI应用开发循环:
- 确定可行性:首先明确AI是否能解决该问题,并定义关键绩效指标(如准确率、延迟)。
- 快速构建端到端系统:使用相对简单的模型和现有工具,快速搭建一个能工作的初始原型系统。这个阶段的目的是验证整个数据流和系统架构,而非追求极致精度。
- 数据驱动的迭代优化:这是最关键的一步。通过分析模型在验证集上的错误,系统地发现并修正数据中的问题。例如,针对模型表现不佳的特定类别,进行针对性的数据收集、清洗或重新标注。然后,用更新后的数据重新训练模型,观察性能提升。这个“分析错误-改进数据-重新训练”的循环应持续进行。
三、对人工智能基础软件开发的启示
吴恩达的要点直接影响了AI基础软件(如训练框架、数据管理平台、模型部署工具)的设计哲学:
- 工具需要支持数据迭代:优秀的AI开发平台不应仅仅是模型训练工具,更应提供强大的数据版本管理、标注流水线、错误分析和数据增强功能,使“以数据为中心”的迭代变得高效。
- 降低端到端部署门槛:基础软件应致力于简化从数据准备到模型部署上线的全过程,让开发者能更专注于业务逻辑和数据处理本身。
- 强调可解释性与错误分析:工具需要提供直观的模型性能诊断和错误归因能力,帮助开发者精准定位数据或模型的薄弱环节。
四、关于“唯一的中文版PPT”
演讲后,吴恩达团队发布的演讲材料(包括PPT)被广泛传播和学习。所谓“唯一的中文版PPT”很可能指的是由热心社区或机构翻译制作的、流传较广的中文版本学习资料。这份材料对于中文世界的开发者和学生理解演讲精髓、降低学习门槛起到了重要作用。它本身也印证了AI知识的开放与共享精神,以及本地化内容在技术普及中的关键价值。
###
吴恩达在NIPS 2016的演讲,实质上是为AI工程化实践绘制了一份蓝图。他倡导的“以数据为中心”的开发理念,以及强调快速原型与系统化迭代的方法论,已经深深植根于现代人工智能应用的开发流程中。对于任何从事人工智能基础软件开发或应用构建的团队而言,重温这些要点,依然能获得关于如何高效、务实推进AI项目的重要启发。